Naïve Bayes Classifier
Naïve Bayes Classifier (NBC) merupakan sebuah pengklasifikasi probabilitas sederhana yang mengaplikasikan Teorema Bayes dengan asumsi ketidaktergantungan (independent) yang tinggi.
Keuntungan penggunan NBC adalah bahwa metoda ini hanya membutuhkan jumlah data pelatihan (training data) yang kecil untuk menentukan estimasi parameter yang diperlukan dalam proses pengklasifikasian.
Karena yang diasumsikan sebagai variable independent, maka hanya varians dari suatu variable dalam sebuah kelas yang dibutuhkan untuk menentukan klasifikasi, bukan keseluruhan dari matriks kovarians.
Model Naïve Bayes Classifier
Secara garis besar model NBC adalah sebagai berikut:
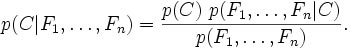
Atau dengan kata lain persamaan diatas dapat digambarkan sebagai:
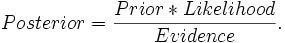
Dalam penggunaannya dalam proses pengklasifikasian dokumen, maka model NBC dapat digambarkan sebagai berikut:
Permasalahan:
Kita akan mengklasifikasikan suatu dokumen berdasarkan isi atau kata-kata yang ada dalam dokumen tersebut. Sebagai contoh adalah apakah sebuah dokumen tersebut merupakan dokumen terkait bidang pendidikan atau tidak.
Untuk itu, kita bayangkan bahwa sebuah dokumen-dokumen diambil dari suatu kelas dokumen (class of document) yang dapat dimodelkan sebagai sebuah himpunan kata-kata, dimana probabilitas (independen) bahwa suatu kata ke-i dalam suatu dokumen terdapat dalam sebuah dokumen yang berasal dari class C. Hal tersebut dapat digambarkan dengan:

(Atau untuk memudahkannya dapat kita asumsikan bahwa probabilitas suatu kata dalam suatu dokumen adalah independen terhadap ukuran suatu dokumen, atau dengan kata lain semua dokumen diasumsikan berukuran sama.)
Selanjutnya probabilitas bahwa sebuah dokumen D, terhadap class C adalah:

Pertanyaannya adalah “Berapa probabilitas suatu dokumen D merupakan milik suatu class C?” atau dengan kata lain adalah berapa nilai probabilitas  ?
?
Berdasarkan aksioma probabilitas:

Dan

Selanjutnya Teorema Bayes digunakan untuk memanipulasi pernyataan probabilitas tersebut diatas menjadi sebuah terminologi likelihood / kemiripan:

Untuk menjawab permasalahan sebelumnya diatas, maka kita asumsikan bahwa hanya terdapat dua kelas, yaitu kelas Spam (S) dan Bukan Spam (~S). Dengan demikian model dapat digambarkan menjadi:

Dan

Dari Teorema Bayes tersebut diatas, dapat kita tuliskan menjadi:


Dengan membagi satu dengan yang lainnya dapat kita gambarkan menjadi:

Model tersebut dapat di-refactor-kan menjadi:

Akhirnya, rasio probabilitas dari p(S | D) / p(¬S | D) dapat diekspresikan dalam suatu terminologi series of likelihood-ratio / rasio kemiripan beruntun.
Selanjutnya, probabilitas aktual dari p(S | D) dapat dengan mudah dihitung melalui log (p(S | D) / p(¬S | D)), berdasarkan pernyataan bahwa p(S | D) + p(¬S | D) = 1.
Dengan mengambil logaritma dari keseluruhan rasio tersebut, maka kita dapatkan:

(tehnik menggunakan log likehood / kemiripan logariitma ini sangat umum digunakan digunakan dalam statistik).
Akhirnya, dokumen dapat diklasifikasikan sebagai berikut.
Dokumen tersebut merupakan Spam apabila :

Dan sebaliknya apabila < 0, maka dokumen tersebut Bukan Spam.
Susah dimengerti, tunggu bahasan selanjutnya
*Derived from wikipedia.org

Tinggalkan komentar